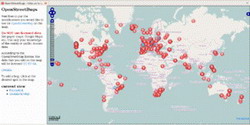
OpenStreetBugs — лёгкий способ сообщить об ошибке в OpenStreetMap
Вы, конечно, знаете о свободной карте OpenStreetMap. Это настоящая народная карта, создаваемая такими же людьми как и вы! Это такой же opensource-проект как Linux и как Википедия.
Конечно же, как и в других картах, в OpenStreetMap имеются ошибки, но в отличие от тех же Яндекс.Карт, где ошибки не исправляются годами из-за сложной бюрократической процедуры (я уже не говорю о намеренных ошибках), в OpenStreetMap всё гораздо проще и лучше для всех нас...
Подробнее..
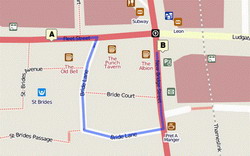
CloudMade Navigation поддерживает ограничения манёвров
Не так давно CloudMade выделил несколько приоритетных направлений, среди которых оказалась и навигация. Решено было создать специальный проект Navi Studio, который объединял бы в себе несколько более мелких сервисов и позволял пользоваться ими, для создания полноценного навигационного программного обеспечения. В Navi Studio вошли:
Работа закипела и уже появилось несколько приложений использующих данный проект. Но полноценной навигации без соблюдения правил ПДД не существует, а потому данному вопросу было также уделено не мало времени...
Подробнее..

Удали себя из интернет-социума — «Web 2.0 Suicide Machine»
Недавно наткнулся в сети на один занимательный интернет-сервис, именующийся Web 2.0 Suicide machine . Предназначен он для того, чтобы позволить людям, обремененным «социальной жизнью в интернете», в пару кликов удалить свои аккаунты на Facebook (в данный момент сервис блокирован администрацией по IP), Twitter, Linkedin
и Myspace. В общем-то судя по количеству положительных отзывов и «успешных очищений» — пипл хавает зависимые от социальных сетей успешно пользуются сервисом и довольны...
Подробнее..
Подсчет количества найденных записей в PostgreSQL

На работе в новом проекте используется СУБД PostgreSQL. Так как до сих пор я работал с MySQL, сейчас приходится изучать и открывать для себя Постгри. Первая проблема, которая меня заинтересовала — замена мускулевского SQL_CALC_FOUND_ROWS. При использовании этой константы в MySQL можно получить количество всех найденных по запросу записей, даже если запрос с limit'ом — это незаменимо при постраничном выводе поисковых результатов, когда используются тяжелые запросы.
Сходу готового решения найти не удалось. На форумах просто констатировали, что SQL_CALC_FOUND_ROWS в Постгри нет. Некоторые писали, что надо юзать count(*). И больше никакой информации. Но еще из MySQL мне было известно, что поиск с count()-запросом работает почти в 2 раза медленнее, чем с SQL_CALC_FOUND_ROWS. Я консультировался у тех, кто пользуется PostgreSQL, день мучал google и в результате получил 4 варианта замены SQL_CALC_FOUND_ROWS в PostgreSQL, один из которых вполне приемлимый по скорости.
Итак, сразу представлю те четыре варианта, о которых пойдет речь. Наш целевой запрос ищет в таблице записи, в которых встречается текст adf в поле `text`. Выбираем id 20 записей начиная от 180.000 по порядку и количество найденных всего.
Вариант 1. Взят из phpPgAdmin. Я просто заглянул в код этого клиента для PostgreSQL и посмотрел как подсчет сделан у них при просмотре данных таблицы. Используется 2 запроса с подзапросами. Удобство в том, что не надо парсить и менять исходный запрос, чтобы подсчитать количество записей, найденных им.
Вариант 2. Самый простой вариант, который обычно юзают новички как в MySQL, так и в Postgres и других СУБД. 2 запроса.
Вариант 3. © max_posedon. Это попытка эмуляции мускулевского SQL_CALC_FOUND_ROWS в Postgres по логике. Правда работает только при сортировке по id (в данном случае). Здесь подставляется id последней записи в выборке, т.е. записи под номером 180.000 + 20.
Вариант 4. По советам пользователей irc.freenode.org, опять же max_posedon‘а, и этого ответа на форуме PostgreSQL, который прятался глубоко в гугле. Используется курсор.
+ фунция PQcmdTuples() API Postgres (или $count = pg_cmdtuples($result); в PHP).
Обратите внимание, что все 4 варианта запросов следует выполнять в одной транзакции, тогда они работают быстрее. 4й вариант вовсе не будет работать, если не использовать одну транзакцию: теряется курсор.
Теперь о скоростях. Я провел тестирование скорости работы этих четырех вариантов. Вобщем-то тесты подтвердили ожидания. Но отмечу важный факт. Все запросы запускались на конфигурации PostgreSQL по умолчанию, которая не является оптимизированной на производительность. У меня под рукой просто не было оптимизированного сервера. Так что цифры могут немного корректироваться при запуске с “хорошим” конфигом. Однако суть не изменится.
Тестовые запуски проводились в PHP по 20 повторов 2 раза на каждый вариант. Доступен php-скрипт, который запускал тесты. Кому интересно, есть полная статистика выборок в Excel™.
| Читайте: |
|---|
 Native Client: одной ногой в офлайнеВ понедельник в Google Code Blog вышел анонс нового эксперимента веб-гиганта. Технология Native Client призвана ускорить веб-приложения благодаря пр... |
 Adobe для веб-разработчиковКомпания Adobe в особом представлении не нуждается – она очень известна практически среди всех пользователей, кто хоть раз имел дело с обработкой гр... |
 Apple выпустит новые продукты к концу годаВ конце 2010 - начале 2011 года в продажу выйдут сразу несколько новых моделей от компании Apple: iPods, iPhone 5 и iPad mini. Как сообщает iloun... |
 Adobe представляет пакет LiveCycle Enterprise Suite 2Компания Adobe Systems Incorporated представила пакет Adobe LiveCycle Enterprise Suite 2 (ES2) – новую версию программного обеспечения, с помощью ко... |
 Google будет конкурировать с Amazon S3Как сообщает TechCrunch, Google собирается представить новый сервис облачного хранения данных, который будет прямым конкурентом Amazon S3. Называтьс... |
Партнеры
Уроки с DLE:

Заметки разработчика:
Модули DLE:


Авторизация
Топ технологий:
 Оздана новая система беспроводной связи - она в 10Ученые из Национального тайваньского университета разработали новую систему беспроводной передачи данных, которая позволит передавать инф... |
 Как взломали TwitterВ Интернетах, наряду с iPad, сканерами в аэропортах и войне между Google и Apple, уже второй день подряд активно обсуждается тема взлома и... |
Популярные статьи:
- LiveStreet
- MySQL против PostgreSQL
- MySQL: установка, настройка, описание
- @font-face или назад в будущее
- Препроцессинг CSS на клиенте
- Основы SQL: запросы к базе данных
- WebKit и expression
- 17 рекомендаций по юзабилити для создания отличной CMS
- Проблема с выделением текста в поле формы у Safari и Сhrome
- XML + CSS = счастье