OpenStreetBugs — лёгкий способ сообщить об ошибке в OpenStreetMap
Вы, конечно, знаете о свободной карте OpenStreetMap. Это настоящая народная карта, создаваемая такими же людьми как и вы! Это такой же opensource-проект как Linux и как Википедия.
Конечно же, как и в других картах, в OpenStreetMap имеются ошибки, но в отличие от тех же Яндекс.Карт, где ошибки не исправляются годами из-за сложной бюрократической процедуры (я уже не говорю о намеренных ошибках), в OpenStreetMap всё гораздо проще и лучше для всех нас...
Подробнее..
CloudMade Navigation поддерживает ограничения манёвров
Не так давно CloudMade выделил несколько приоритетных направлений, среди которых оказалась и навигация. Решено было создать специальный проект Navi Studio, который объединял бы в себе несколько более мелких сервисов и позволял пользоваться ими, для создания полноценного навигационного программного обеспечения. В Navi Studio вошли:
Работа закипела и уже появилось несколько приложений использующих данный проект. Но полноценной навигации без соблюдения правил ПДД не существует, а потому данному вопросу было также уделено не мало времени...
Подробнее..

Удали себя из интернет-социума — «Web 2.0 Suicide Machine»
Недавно наткнулся в сети на один занимательный интернет-сервис, именующийся Web 2.0 Suicide machine . Предназначен он для того, чтобы позволить людям, обремененным «социальной жизнью в интернете», в пару кликов удалить свои аккаунты на Facebook (в данный момент сервис блокирован администрацией по IP), Twitter, Linkedin
и Myspace. В общем-то судя по количеству положительных отзывов и «успешных очищений» — пипл хавает зависимые от социальных сетей успешно пользуются сервисом и довольны...
Подробнее..
Oracle RAC. Общее описание
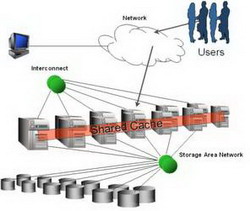
Высоконагруженные сайты, доступность «5 nines». На заднем фоне (backend) куча обрабатываемой информации в базе данных. А что, если железо забарахлит, если вылетит какая-то давно не проявлявшаяся ошибка в ОС, упадет сетевой интерфейс? Что будет с доступностью информации? Из чистого любопытства я решил рассмотреть, какие решения вышеперечисленным проблемам предлагает Oracle. Последние версии, в отличие от Oracle 9i, называются Oracle 10g (или 11g), где g – означает «grid», распределенные вычисления. В основе распределенных вычислений «как ни крути» лежат кластера, и дополнительные технологии репликации данных (DataGuard, Streams). В этой статье в общих чертах описано, как устроен кластер на базе Oracle 10g. Называется он Real Application Cluster (RAC).
Статья не претендует на полноту и всеобъемлемость, также в ней исключены настройки (дабы не увеличивать в объеме). Смысл – просто дать представление о технологии RAC.
Статью хотелось написать как можно доступнее, чтобы прочесть ее было интересно даже человеку, мало знакомому с СУБД Oracle. Поэтому рискну начать описание с аспектов наиболее часто встречаемой конфигурации БД – single-instance, когда на одном физическом сервере располагается одна база данных (RDBMS) Oracle. Это не имеет непосредственного отношения к кластеру, но основные требования и принципы работы будут одинаковы.
Введение. Single-instance.
Наиболее распространенная база данных, установленная на одном физическом сервере, называется single-instance. Я раньше не предавал особого значения разнице понятий между: экземпляр (instance) базы данных и самой базы данных (в целом). Теперь же хочу особенно отметить, что под экземпляром подразумевается ПО (процессы, потоки, сервисы) которое располагается в оперативной памяти и обрабатывает данные (сортировка, буферизация, обслуживание) полученные непосредственно с диска. Таким образом, под базой данных подразумевается совокупность:
область хранения данных, т.е. физические файлы на диске (datastorage) (сама БД)
экземпляр БД (получающая и обрабатывающая эти данные в оперативной памяти) (СУБД)
Во всех современных реляционных БД данные хранятся в таблицах. Таблицы, индексы и другие объекты в Oracle хранятся в логических контейнерах – табличных пространствах (tablespace). Физически же tablespace располагаются в одном или нескольких файлах на диске. Хранятся они следующим образом:
Каждый объект БД (таблицы, индексы, сегменты отката и.т.п.) хранится в отдельном сегменте – области диска, которая может занимать пространство в одном или нескольких файлах. Сегменты в свою очередь, состоят из одного или нескольких экстентов. Экстент – это непрерывный фрагмента пространства в файле. Экстенты состоят из блоков. Блок – наименьшая единица выделения пространства в Oracle, по умолчанию равная 8K. В блоках хранятся строки данных, индексов или промежуточные результаты блокировок. Именно блоками сервер Oracle обычно выполняет чтение и запись на диск. Блоки имеют адрес, так называемый DBA (Database Block Address).
При любом обращении DML (Data Manipulation Language) к базе данных, Oracle подгружает соответствующие блоки с диска в оперативную память, а именно в буферный кэш. Хотя возможно, что они уже там присутствуют, и тогда к диску обращаться не нужно. Если запрос изменял данные (update, insert, delete), то изменения блоков происходят непосредственно в буферном кэше, и они помечаются как dirty (грязные). Но блоки не сразу сбрасываются на диск. Ведь диск – самое узкое место любой базы данных, поэтому Oracle старается как можно меньше к нему обращаться. Грязные блоки будут сброшены на диск автоматически фоновым процессом DBWn при прохождении контрольной точки (checkpoint) или при переключении журнала.
Предположим, что была запущена одна длительная транзакция, считывающая данные, и где-то в процессе ее выполнения запустилась другая транзакция с намерением изменить один из считываемых блоков. Как сервер скоординирует работу этих запросов? На самом деле, вопрос разделяется на два:
Что будет, если Oracle упадет где-то на середине длинной транзакции (если бы она вносила изменения)?
Какие же данные прочтет первая транзакция, когда в кэше у нее «под носом» другая транзакция изменила блок?
Для ответа на эти вопросы рассмотрим механизм обеспечения согласованного чтения CR (consistency read). Все дело в волшебных пузырьках журналах транзакций, которые в Oracle представлены двумя типами:
журнал повтора (redo log)
сегмент отмены (undo)
Когда в базу данных поступает запрос на изменение, то Oracle применяет его в буферном кэше, параллельно внося информацию, достаточную для повторения этого действия, в буфер повторного изменения (redo log buffer), находящийся в оперативной памяти. Как только транзакция завершается, происходит ее подтверждение (commit), и сервер сбрасывает содержимое redo buffer log на диск в redo log в режиме append-write и фиксирует транзакцию. Такой подход гораздо менее затратен, чем запись на диск непосредственно измененного блока. При сбое сервера кэш и все изменения в нем потеряются, но файлы redo log останутся. При включении Oracle начнет с того, что заглянет в них и повторно выполнит изменения таблиц (транзакции), которые не были отражены в datafiles. Это называется «накатить» изменения из redo, roll-forward. Online redo log сбрасывается на диск (LGWR) при подтверждении транзакции, при прохождении checkpoint или каждые 3 секунды (default).
С undo немного посложнее. С каждой таблицей в соседнем сегменте хранится ассоциированный с ней сегмент отмены. При запросе DML вместе с блоками таблицы обязательно подгружаются данные из сегмента отката и хранятся также в буферном кэше. Когда данные в таблице изменяются в кэше, в кэше так же происходит изменение данных undo, туда вносятся «противодействия». То есть, если в таблицу был внесен insert, то в сегмент отката вносится delete, delete – insert, update – вносится предыдущее значение строки. Блоки (и соответствующие данные undo) помечаются как грязные и переходят в redo log buffer. Да-да, в redo журнал записываются не только инструкции, какие изменения стоит внести (redo), но и какие у них противодействия (undo). Так как LGWR сбрасывает redo log buffer каждые 3 секунды, то при неудачном выполнении длительной транзакции (на пару минут), когда после минуты сервер упал, в redo будут записи не завершенные commit. Oracle, как проснется, накатит их (roll-forward), и по восстановленным (из redo log) в памяти сегментам отката данных отменит (roll-back) все незафиксированные транзакции. Справедливость восстановлена.
Кратко стоит упомянуть еще одно неоспоримое преимущество undo сегмента. По второму сценарию (из схемы) когда select дойдет до чтения блока (DBA) 500, он вдруг обнаружит что этот блок в кэше уже был изменен (пометка грязный), и поэтому обратится к сегменту отката, для того чтобы получить соответствующее предыдущее состояние блока. Если такого предыдущего состояния (flashback) в кэше не присутствовало, он прочитает его с диска, и продолжит выполнение select. Таким образом, даже при длительном «select count(money) from bookkeeping» дебет с кредитом сойдется. Согласованно по чтению (CR).
| Читайте: |
|---|
Партнеры
Уроки с DLE:


Заметки разработчика:
Модули DLE:


Авторизация
Топ технологий:
 Оздана новая система беспроводной связи - она в 10Ученые из Национального тайваньского университета разработали новую систему беспроводной передачи данных, которая позволит передавать инф... |
 Как взломали TwitterВ Интернетах, наряду с iPad, сканерами в аэропортах и войне между Google и Apple, уже второй день подряд активно обсуждается тема взлома и... |
Популярные статьи:
- LiveStreet
- MySQL против PostgreSQL
- MySQL: установка, настройка, описание
- @font-face или назад в будущее
- Препроцессинг CSS на клиенте
- Основы SQL: запросы к базе данных
- WebKit и expression
- 17 рекомендаций по юзабилити для создания отличной CMS
- Проблема с выделением текста в поле формы у Safari и Сhrome
- XML + CSS = счастье