OpenStreetBugs — лёгкий способ сообщить об ошибке в OpenStreetMap
Вы, конечно, знаете о свободной карте OpenStreetMap. Это настоящая народная карта, создаваемая такими же людьми как и вы! Это такой же opensource-проект как Linux и как Википедия.
Конечно же, как и в других картах, в OpenStreetMap имеются ошибки, но в отличие от тех же Яндекс.Карт, где ошибки не исправляются годами из-за сложной бюрократической процедуры (я уже не говорю о намеренных ошибках), в OpenStreetMap всё гораздо проще и лучше для всех нас...
Подробнее..
CloudMade Navigation поддерживает ограничения манёвров
Не так давно CloudMade выделил несколько приоритетных направлений, среди которых оказалась и навигация. Решено было создать специальный проект Navi Studio, который объединял бы в себе несколько более мелких сервисов и позволял пользоваться ими, для создания полноценного навигационного программного обеспечения. В Navi Studio вошли:
Работа закипела и уже появилось несколько приложений использующих данный проект. Но полноценной навигации без соблюдения правил ПДД не существует, а потому данному вопросу было также уделено не мало времени...
Подробнее..

Удали себя из интернет-социума — «Web 2.0 Suicide Machine»
Недавно наткнулся в сети на один занимательный интернет-сервис, именующийся Web 2.0 Suicide machine . Предназначен он для того, чтобы позволить людям, обремененным «социальной жизнью в интернете», в пару кликов удалить свои аккаунты на Facebook (в данный момент сервис блокирован администрацией по IP), Twitter, Linkedin
и Myspace. В общем-то судя по количеству положительных отзывов и «успешных очищений» — пипл хавает зависимые от социальных сетей успешно пользуются сервисом и довольны...
Подробнее..
Технология, опробованная Google, вызывает все больший интерес у разработчиков реляционных баз данных
Кто говорит, что между традиционными производителями СУБД, построенными на фундаменте SQL, и сторонниками так называемой технологии NoSQL идет война?
Множество производителей реляционных СУБД, от компаний-стартапов, предлагающих спецсерверы хранилищ данных с массивной параллельной обработкой, до признанных корифеев, накопивших опыт оперативной обработки транзакций, переходят к технологии обработки данных MapReduce, разработанной компанией Google.
Sybase стала одним из последних производителей, кто присоединился к этому движению. Директор Sybase по технологии Ирфан Хан объявил, что его компания сейчас работает над интеграцией функциональности MapReduce в свою популярную аналитическую СУБД Sybase IQ.
Новая функциональность должна помочь Sybase IQ быстрее обрабатывать больший объем данных, подчеркнул Хан. Sybase IQ — самая устоявшаяся из СУБД, базирующихся на архитектуре столбцов, широко используется для бизнес-аналитики и аналитических приложений.
«Благодаря интеграции MapReduce и подходу, предусматривающему поддержку определяемых пользователем функций, мы сможем перенести обработку ближе к месту размещения данных и при этом сохранить привычный SQL-подобный интерфейс», — особо отметил Хан.
Недавно созданные компании Aster Data и Greenplum стали инициаторами поддержки NoSQL в 2008 году, когда объявили о намерении добавить поддержку технологии MapReduce к своим приложениям хранилищ данных, чтобы ускорить обработку больших наборов аналитической информации.
Сторонники этого подхода утверждают, что MapReduce, наряду с родственным ему свободно распространяемым Java-проектом Hadoop, быстрее, чем реляционные базы данных, обрабатывает большие массивы информации (сотни терабайтов или даже петабайтов), распределенные по крупномасштабной сети серверов, подобной сетям поисковых серверов Google.
Первыми MapReduce и Hadoop начали применять у себя компании, работающие в Web, такие как Yahoo, Facebook и LinkedIn, предъявляющие те же требования к обработке данных, что и Google.
Между тем сторонники SQL утверждают, что преимущества MapReduce и Hadoop выявляются только при определенных типах обработки данных, таких как индексация текстов и добыча данных, а язык и инструментарий SQL работают быстрее и лучше удовлетворяют разнообразные требования большинства предприятий.
Однако, если судить по отзывам компаний, представленным на состоявшейся прошлой осенью конференции HadoopWorld, интерес к новой технологии довольно заметен. В частности, на конференции выступили представители Visa, JP Morgan Chase, Booz Allen, New York Times и China Mobile.
Один из пионеров рынка реляционных баз данных, Майкл Стоунбрекер, стал соавтором статьи, в которой утверждается, что технология SQL в большинстве случаев по-прежнему превосходит MapReduce. Однако эти выводы не повлияли на политику компании Vertica Systems, где Стоунбрекер работает директором по технологии, и она объявила о намерении добавить поддержку функциональности Hadoop в версию 3.5 своей СУБД Vertica.
На действиях трех ведущих производителей традиционных реляционных СУБД, по-видимому, сказывается тот факт, что корпоративные клиенты все чаще вместо оперативной обработки транзакций первоочередное внимание уделяют аналитике.
В октябре представители IBM сообщили, что компания разработала веб-сервис на базе технологии Hadoop, получивший название M2. Однако пока неизвестно, намерена ли компания использовать эту технологию для своих реляционных СУБД DB2 или Informix.
Microsoft, как сообщается, встроит возможности, аналогичные MapReduce, в следующую версию СУБД SQL Server 2008, известную под кодовым названием Madison.
Корпорация Oracle в свою очередь объявила, что уже интегрировала поддержку MapReduce в свою СУБД.
Аналитик Курт Монаш отметил, что на него произвела большое впечатление интеграция SQL и MapReduce, реализованная компанией Aster Data. «Я глубоко благодарен ребятам из SAS Institute, партнера Aster, за такую работу», — сказал он.
Разрежь и посчитай
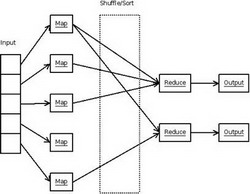
Создание MapReduce открыло возможность для обработки огромных массивов данных.
Допустим, что следует решить простейшую задачу: обработать массив, разбив его на подмассивы. В таком случае работа Мастера сводится к тому, что он делит этот массив на части, посылает каждому из Рабочих положенный ему подмассив, а затем получает результаты и объединяет их. В функцию Рабочего входит получение данных, обработка и возврат результатов Мастеру. Распределение нагрузок может быть статическим (static) или динамическим (dynamic). Концепция создана по мотивам комбинации map и reduce в функциональном языке программирования Лисп. В нем map использует в качестве входных параметров функцию и набор значений, применяя эту функцию по отношению к каждому из значений, а reduce комбинирует полученные результаты.
Созданная в Google конструкция MapReduce делает примерно то же, но по отношению к гигантским объемам данных. В этом случае map — это функция запроса от пользователя, помещенная в библиотеку MapReduce. Ее работа сводится к выбору входной пары, ее обработке и формированию результата в виде значения и некоторого промежуточного ключа, служащего указателем для reduce. Конструкция MapReduce собирает вместе все значения с одинаковыми промежуточными ключами и передает их в функцию reduce, также написанную пользователем. Эта функция воспринимает промежуточные значения, каким-то образом их собирает и воспроизводит результат, скорее всего выраженный меньшим количеством значений, чем входное множество.
...Вызовы map распределяются между множеством машин путем деления входного потока данных на М срезов, каждый срез обрабатывается на отдельной машине. Вызовы reduce распределены на R частей, количество которых определяется пользователем.
При вызове функции из библиотеки MapReduce выполняется примерно такая последовательность операций.
1. Входные файлы разбиваются на срезы..., и на кластере запускаются копии программы. Одна из них Мастер, а остальные — Рабочие. Всего создается M задач map и R задач reduce. Поиском свободных узлов и назначением на них задач занимается Мастер.
2. В процессе исполнения Рабочие (копии программ — Прим. ред.), назначенные на выполнение задачи map, считывают содержимое соответствующих срезов, осуществляют их грамматический разбор, выделяют отдельные пары «ключ и соответствующее ему значение», а потом передают эти пары в обрабатывающую их функцию map. Промежуточное значение в виде идентификатора и значения буферизуется в памяти.
3. Периодически буферизованные пары сбрасываются на локальный диск, разделенный на R областей. Расположение этих пар передается Мастеру, который отвечает за дальнейшую передачу этих адресов Рабочим, выполняющим reduce.
4. Рабочие, выполняющие задачу reduce, ждут сообщения от Мастера о местоположении промежуточных пар. По его получении они, используя процедуры удаленного вызова, считывают буферизованные данные с локальных дисков тех Рабочих, которые выполняют map. Загрузив все промежуточные данные, Рабочий сортирует их по промежуточным ключам и, если есть необходимость, группирует.
5. Рабочий обрабатывает данные по промежуточным ключам и передает их в соответствующую функцию reduce для вывода результатов.
6. Когда все задачи map и reduce завершаются, конструкция MapReduce возобновляет работу вызывающей программы и та продолжает выполнять пользовательский код.
Одно из важнейших преимуществ этой, замысловатой на первый взгляд конструкции состоит в том, что она позволяет надежно работать на платформах с низкими показателями надежности. Для обнаружения потенциальных сбоев Мастер периодически опрашивает Рабочих, и, если какой-то из них задерживается с ответом сверх заданного норматива, Мастер считает его дефектным и передает исполнение на свободные узлы. Различие между задачами map и reduce в данном случае состоит в том, что map хранит промежуточные результаты на своем диске, и выход из строя такого узла приводит к их потере и требует повторного запуска, а reduce хранит свои данные в глобальном хранилище.
— Из статьи Леонида Черняка «MapReduce — будущее баз данных»
(«Открытые системы»
| Читайте: |
|---|
Партнеры
Уроки с DLE:


Заметки разработчика:
Модули DLE:


Авторизация
Топ технологий:
 Оздана новая система беспроводной связи - она в 10Ученые из Национального тайваньского университета разработали новую систему беспроводной передачи данных, которая позволит передавать инф... |
 Как взломали TwitterВ Интернетах, наряду с iPad, сканерами в аэропортах и войне между Google и Apple, уже второй день подряд активно обсуждается тема взлома и... |
Популярные статьи:
- LiveStreet
- MySQL против PostgreSQL
- MySQL: установка, настройка, описание
- @font-face или назад в будущее
- Препроцессинг CSS на клиенте
- Основы SQL: запросы к базе данных
- WebKit и expression
- 17 рекомендаций по юзабилити для создания отличной CMS
- Проблема с выделением текста в поле формы у Safari и Сhrome
- XML + CSS = счастье